 Костромин Владимир Викторович
Костромин Владимир ВикторовичПолитолог, [email protected]
Использование голосов избирателями в многомандатных округах с плюральным правилом: агрегированный анализ на примере российских муниципальных выборов
Аннотация
Система относительного большинства в многомандатных округах (MNTV) предоставляет избирателям несколько голосов, которые они могут использовать по своему усмотрению. Представляется, что число использованных избирателями голосов может являться важным показателем, описывающим функционирование данной избирательной системы. Однако в большинстве случаев предыдущие исследования используют его только в качестве вспомогательного показателя и редко пытаются объяснить, с чем может быть связано его изменение. В данном исследовании предпринята попытка представить число голосов, используемых избирателями, как отражение соотношения между существующим электоральным спросом и предложением со стороны партий и кандидатов. Такая концептуальная рамка позволяет предполагать, что неиспользование части доступных голосов может быть связано с недостаточным удовлетворением электорального спроса. Соответственно возникновение необходимого предложения должно быть связано с использованием большего числа голосов. Опора на такой подход позволяет выдвигать эмпирически проверяемые гипотезы, позволяющие объяснить, в каких условиях избиратели активнее или реже применяют доступные голоса. В рамках данной работы электоральный спрос рассматривается с опорой на возможные критерии отбора кандидатов избирателями, основанные на моделях голосования. Эти предположения проверяются на широком наборе данных российских муниципальных выборов, охватывающих города РФ, а также внутригородские муниципальные образования Москвы и Санкт-Петербурга в период с 2007 по 2021 г. Полученные результаты демонстрируют, что использование голосов российскими избирателями в большей степени соответствует «свободной» модели голосования, которая предполагает отбор кандидатов на основе их индивидуальных параметров. Напротив, «партийная» модель голосования, подразумевающая поддержку только кандидатов предпочитаемой партии, получает слабую эмпирическую поддержку.
Введение
Система относительного большинства в многомандатных округах (MNTV [11: 14–15]) предоставляет избирателям несколько голосов. Они могут использовать их на свое усмотрение: воспользоваться минимумом, частью или потратить их все [18: 44]. Такая особенность дает электорату гибкие возможности для выражения собственных предпочтений. Хотя представляется, что интенсивность применения голосов избирателями может являться важной частью избирательной системы MNTV [25: 472], большинство исследований используют данный показатель только в качестве описательной меры или ограничиваются проверкой возможных корреляций [10: 930; 17: 115–116; 24: 225, 278–279, 300; 25: 472–474; 26]. Только небольшое количество работ анализирует, с какими условиями связано использование большего или меньшего числа голосов избирателями [16].
В данной работе предпринята попытка предложить концептуальную схему, которая рассматривает число используемых голосов избирателями как взаимодействие возникающего электорального спроса и существующего предложения со стороны партий и кандидатов. Предполагается, что избиратели готовы использовать доступные им голоса, когда спрос удовлетворяется предложением, и наоборот. Данный подход предполагает обнаружение факторов электорального предложения, с которыми в наибольшей степени связано использование голосов. Полученные результаты позволяют предполагать, какой вид электорального спроса в большей степени распространен среди избирателей.
Электоральный спрос в данном случае рассматривается как принцип отбора подходящих кандидатов. Подходы к такому выбору могут быть описаны через предпочитаемые избирателями модели голосования в MNTV. Так, «партийная» модель голосования предполагает, что избиратель голосует только за кандидатов предпочитаемой партии. В таком случае использовать все голоса возможно, если поддерживаемая партия обладает полным представительством в округе. «Свободная» модель голосования предусматривает отбор кандидатов избирателями на основе собственных предпочтений. Применение всех доступных голосов возможно, если избиратель находит кандидатов, которые соответствуют его взглядам. Обнаружение свидетельств в пользу определенных видов электорального спроса позволяет предположить возможные последствия системы MNTV.
Однако проведение такого рода анализа чаще всего осложняется отсутствием данных об индивидуальном использовании голосов избирателями. В данной работе предлагается использовать среднюю долю использованных дополнительных голосов избирателями в качестве наиболее удобной и удачной меры агрегированной оценки числа используемых голосов. Преимуществом данного подхода является единый диапазон шкалы вне зависимости от величины используемого избирательного округа.
Поиск взаимосвязей между факторами электорального предложения и агрегированной оценкой числа используемых голосов проводится на данных российских муниципальных выборов с применением системы MNTV. Предыдущие исследования отмечали, что российские избиратели достаточно редко используют доступный им потенциал голосов [10: 930; 24: 225, 278–279, 300; 25: 472–474; 26]. Данная работа стремится продемонстрировать, какие факторы электорального предложения в большей степени связаны с более интенсивным использованием голосов избирателями.
Описанный анализ проводится на широком наборе данных российских муниципальных выборов. Он охватывает три электоральных цикла с 2007 по 2021 г., включая выборы в различные муниципальные образования в российских регионах. Стратегия анализа основывается на применении смешанной многоуровневой регрессионной модели, которая позволяет учесть иерархический характер данных. Полученные результаты в большей степени согласуются с предположением о более частом использовании российскими избирателями «свободной», а не «партийной» модели голосования.
Использование голосов в системе относительного большинства в многомандатных округах
Система относительного большинства в многомандатных округах, также называемая Multiple Non-Transferable Vote (MNTV) [11: 14–15], представляет собой электоральную систему, где у избирателей имеется сразу несколько голосов. Их число равно количеству распределяемых мест в избирательном округе (\(V = M\)) [18: 44]. Избиратели голосуют за отдельные кандидатуры, имея возможность выбрать одновременно представителей разных партий. Однако каждый кандидат может быть поддержан только единожды, т.е. возможность для кумулятивного голосования отсутствует. Места выигрывают \(M\) кандидатов, получивших относительное большинство голосов в избирательном округе.
Такое сочетание избирательных правил предоставляет электорату широкие возможности для голосования [6; 12; 17]. Наличие нескольких голосов, а также возможность выбора представителей от разных партий позволяют избирателям формировать комбинации кандидатов, которые наилучшим образом представляют имеющиеся предпочтения. Кроме того, возможность использования только части имеющихся голосов [18: 44] также расширяет возможности для голосования. Наличие такой опции позволяет выразить поддержку только наиболее подходящим кандидатам и не способствовать победе тем, кто не соответствует по каким-либо причинам.
Число используемых голосов избирателями представляется важным показателем, описывающим функционирование системы MNTV [25: 472–474]. Его значение может указывать на соответствие между имеющимся у избирателей электоральным спросом и возникающим со стороны партий или кандидатов предложением. Если большая часть электората не использует доступные им голоса, то это может являться свидетельством в пользу существования разрыва между необходимыми электорату кандидатами и доступными для выбора [16: 5]. Имеющийся у избирателей спрос может быть вариативен и неоднороден. Однако его возможно рассмотреть с точки зрения возможных подходов к голосованию в MNTV, что позволит выделить отличные типы электорального спроса.
Модели голосования в MNTV являются идеальными типами, которые описывают подходы к голосованию на основе отбора кандидатов избирателями. Так, электорат может рассматривать проходящие выборы или как состязание партий, или как соперничество между отдельными кандидатурами [6: 266–268]. Каждый из представленных подходов формирует отличную модель отбора подходящих кандидатов. В первом случае, что можно описать как «партийную» модель, выбор ограничивается представителями предпочитаемой партии. Во втором случае, что можно представить как «свободную» модель, избиратели рассматривают всех кандидатов, отбирая наиболее подходящих в соответствии с собственными предпочтениями. Последствия использования системы MNTV могут зависеть от преобладающей среди электората модели голосования [12: 104–105], что делает ее важной частью функционирования данной избирательной системы.
Электоральный спрос избирателей формируется используемой моделью голосования. Такая особенность возникает ввиду того, что каждая из них по-разному определяет, какие из доступных кандидатов являются подходящими. Однако, вне зависимости от используемой модели и формируемого ею спроса, механизм использования голосов не различается: избиратель использует доступные голоса, если для этого есть подходящие ему кандидаты. В более формальном виде это означает, что на имеющийся у него электоральный спрос приходится соответствующее предложение. В обратном случае, если предложение меньше спроса, то возможно использовать только часть из имеющихся голосов. Поскольку каждая из моделей задает собственный вариант спроса, подробнее рассмотрим, на основании чего он формируется.
«Партийная» модель голосования предполагает, что избиратель в большей степени опирается на партийные ярлыки при голосовании [19: 560–561]. Так, он поддерживает предпочитаемую партию, голосуя за каждого из выставленного ею кандидата и игнорируя любых других баллотирующихся. Такая модель голосования подразумевает, что избиратель обладает спросом только на представителей поддерживаемой партии. Предложением в таком случае выступает число таких кандидатов на выборах. Из этого следует, что избиратель, полагающийся на «партийную» модель, использует все доступные голоса, если на каждый доступный голос приходится кандидат поддерживаемой партии. В обратном случае, если имеющееся предложение недостаточно, то есть количество необходимых кандидатов меньше числа располагаемых голосов, то используется только их часть, ввиду неполного удовлетворения спроса.
«Свободная» модель голосования подразумевает, что избиратель рассматривает всех доступных ему кандидатов, не ограничивая себя какой-либо одной партией [17: 113]. Для того чтобы сделать среди них осознанный выбор, он определяет некоторые важные параметры кандидатов, опираясь на имеющиеся у него предпочтения. Далее избиратель, используя эти сформированные критерии, отбирает наиболее подходящих кандидатов и голосует за них.
Такой подход подразумевает, что каждый избиратель обладает собственным вариантом спроса, который основывается на его представлениях. Он выражается в виде кандидатов с некоторыми необходимыми параметрами. Такими критериями могут выступать важные для избирателя социально-демографические характеристики, идеологическая позиция, мнение по конкретной политике и т.д. Из этого следует, что спрос конкретного избирателя будет удовлетворен, если в выборах участвует необходимое число кандидатов, подходящих под выбранные им параметры. Соответственно предложением выступает количество подходящих по заданным условиям кандидатов. В таком случае, чем больше кандидатов соответствуют сформированным критериям, тем большее число голосов будет использовано, и наоборот.
Концептуализация использования доступных голосов в MNTV как взаимодействия между электоральным спросом и предложением позволяет предположить, в каких условиях используется большее число голосов, а в каких меньшее. Такой подход позволяет утверждать, что избирателю для использования каждого дополнительного голоса необходимо наличие дополнительного кандидата, соответствующего требуемому спросу. Использование всех доступных избирателю голосов возможно при соответствии имеющегося электорального спроса и предложения. Если же такое соотношение достигается лишь частично, то используется только часть из них. В наиболее радикальном случае, если электоральный спрос не удовлетворяется вовсе, избиратель может отказаться от голосования.
Данный подход к анализу использования голосов исходит из предположения, что избиратель заинтересован в применении всех доступных голосов. Из этого следует, что каждый голос имеет одинаковую ценность и реализация каждого из них одинаково полезна. В таком случае использование каждого последующего голоса зависит лишь от наличия возможностей для этого. Также изначальное предположение подразумевает, что избиратели, которые не готовы использовать все доступные голоса, будут обладать иным механизмом реализации голосов. Представляется, что их участие в выборах не должно помешать анализу, так как они руководствуются иными стимулами.
Таким образом, число голосов, используемых избирателями в MNTV, может являться важным показателем, отражающим разницу между формируемым избирателями спросом и имеющимся на выборах предложением со стороны партий и кандидатов. Большое число неиспользованных голосов может свидетельствовать в пользу серьезного разрыва между данными структурными факторами и наоборот. Кроме того, обнаружение устойчивых и существенных связей между различными факторами электорального предложения и потенциалом использования голосов может свидетельствовать в пользу определенных моделей голосования, позволяя лучше понимать функционирование MNTV.
Оценка числа использованных голосов
Непосредственная оценка числа использованных голосов требует данных о голосовании каждого из участвующих избирателей. Однако в большинстве случаев такая информация недоступна. Результаты выборов чаще всего представлены в виде агрегированных результатов партий или кандидатов в пределах определенной территории: участка, округа, и т. д. Такое ограничение позволяет вычислить число использованных голосов избирателями только в агрегированном виде.
Такая оценка представляет собой среднее число использованных голосов избирателями в пределах некоторой территории. Для удобства в дальнейшем будем предполагать, что она вычисляется на уровне избирательного участка (\(i\)). Для ее расчета необходимо использовать данные о том, какое суммарное количество голосов было отдано избирателями (\(VT\) – Voters Total), что может быть вычислено как сумма всех голосов, полученных кандидатами. Также необходимо знать число избирателей, чьи голоса являются действительными (\(VB\) – Valid Ballots). Отношение двух данных величин определяется как среднее число использованных голосов избирателями (\(AUV\) – Average Used Votes):
$$AUV_{id} = \frac{VT_{id}}{VB_{id}}=\frac{\sum_{1}^{N_{d}}v_{cid}}{VB_{id}}\quad(1) ,$$
где \(i\) – номер избирательного участка, \(d\) – номер избирательного округа, \(N_d\) – число кандидатов в округе \(d\), \(c\) – идентификатор кандидата, участвующего в выборах, \(V_{cid}\) – число голосов, полученных кандидатом \(c\) на избирательном участке \(i\) в избирательном округе \(d\).
Среднее число использованных голосов (\(AUV_{id}\)) представляет собой агрегированное значение, которое отражает, сколько голосов в среднем использовали избиратели на конкретном избирательном участке. Возможный диапазон данной переменной определяется величиной избирательного округа и составляет от 1 до \(M\). Из этого следует, что чем ближе полученное значение к 1, тем меньшее число голосов в среднем использовали избиратели. Чем ближе данное значение к \(M\), тем большее число голосов в среднем было использовано.
Среднее число использованных голосов избирателями необязательно соотносится с наиболее частым вариантом применения голосов избирателями на некотором участке. Из-за того что данная мера является агрегированным значением, возможны случаи, когда наиболее используемое число голосов среди избирателей конкретного участка кардинально отличается от усредненного значения. Таким образом, данный показатель стоит интерпретировать как значение, отражающее, насколько полноценно избиратели используют доступные им голоса в среднем.
Недостатком такого подхода к оценке агрегированного числа использованных голосов является зависимость масштаба от величины избирательного округа. Данная особенность критична в условиях изучения округов с разной величиной. Поэтому полезным представляется сформировать вариант оценки с единым диапазоном. Для этого необходимо воспользоваться min-max нормализацией.
Данная процедура требует корректировки числителя и знаменателя среднего числа использованных голосов (\(AUV\)). Из числителя необходимо вычесть минимально возможное число голосов, которое могло быть отдано избирателями. Данная величина равна действительному числу бюллетеней (\(VB\)). Тогда как знаменатель необходимо умножить на максимально возможное число дополнительных голосов. Данный показатель выражается как величина округа минус один (\(M - 1\)). Таким образом, в числителе будет находиться суммарное количество дополнительных голосов, отданное избирателями (\(AVT\) – Additional Votes Total), в то время как знаменатель будет содержать максимально возможное число дополнительных голосов, доступных избирателям (\(AVP\) – Additional Votes Potential). В таком случае итоговая формула выглядит так:
$$ASUAV_{id} = \frac{AVT_{id}}{AVP_{id}} = \frac{VT_{id} - VB_{id}}{VB_{id} \times (M_{d} - 1)}\quad(2) ,$$
Такое преобразование создает единую шкалу, где 0 – использование одного голоса, тогда как 1 – применение \(M\) голосов. В таком случае данную переменную лучше всего представить как среднюю долю использованных дополнительных голосов (\(ASUAV\) – Average share of used additional votes). Она отражает, какую долю дополнительных голосов в среднем использовали избиратели. Чем ближе значение к 1, тем большая доля дополнительных голосов была использована избирателями в среднем, и наоборот. Иными словами, данная мера показывает интенсивность использования дополнительных доступных голосов избирателями.
Такая интерпретация показателя возникает ввиду изменения стартовой точки отсчета. Поскольку данный показатель охватывает только действительные бюллетени, использование хотя бы одного голоса является необходимым условием. Оставшиеся доступные голоса (2, M) могут рассматриваться как дополнительные. Фокусирование на них представляет наибольший интерес, потому как степень их использования напрямую зависит от соответствия между электоральным спросом и предложением.
Визуализация взаимосвязи между средним числом использованных голосов (\(AUV\)) и средней долей использованных дополнительных голосов (\(ASUAV\)) представлена на рисунке 1. Как можно заметить, для разных вариантов величины округа наблюдается линейная связь, которая отличается только возможным наклоном. Данное обстоятельство позволяет переводить значения из одного в другое:
$$AUV_{id} = ASUAV_{id} \times (M_{d} - 1) + 1\quad(3)$$
$$ASUAV_{id} = \frac{AUV_{id} - 1}{(M_{d} - 1)}\quad(4) $$
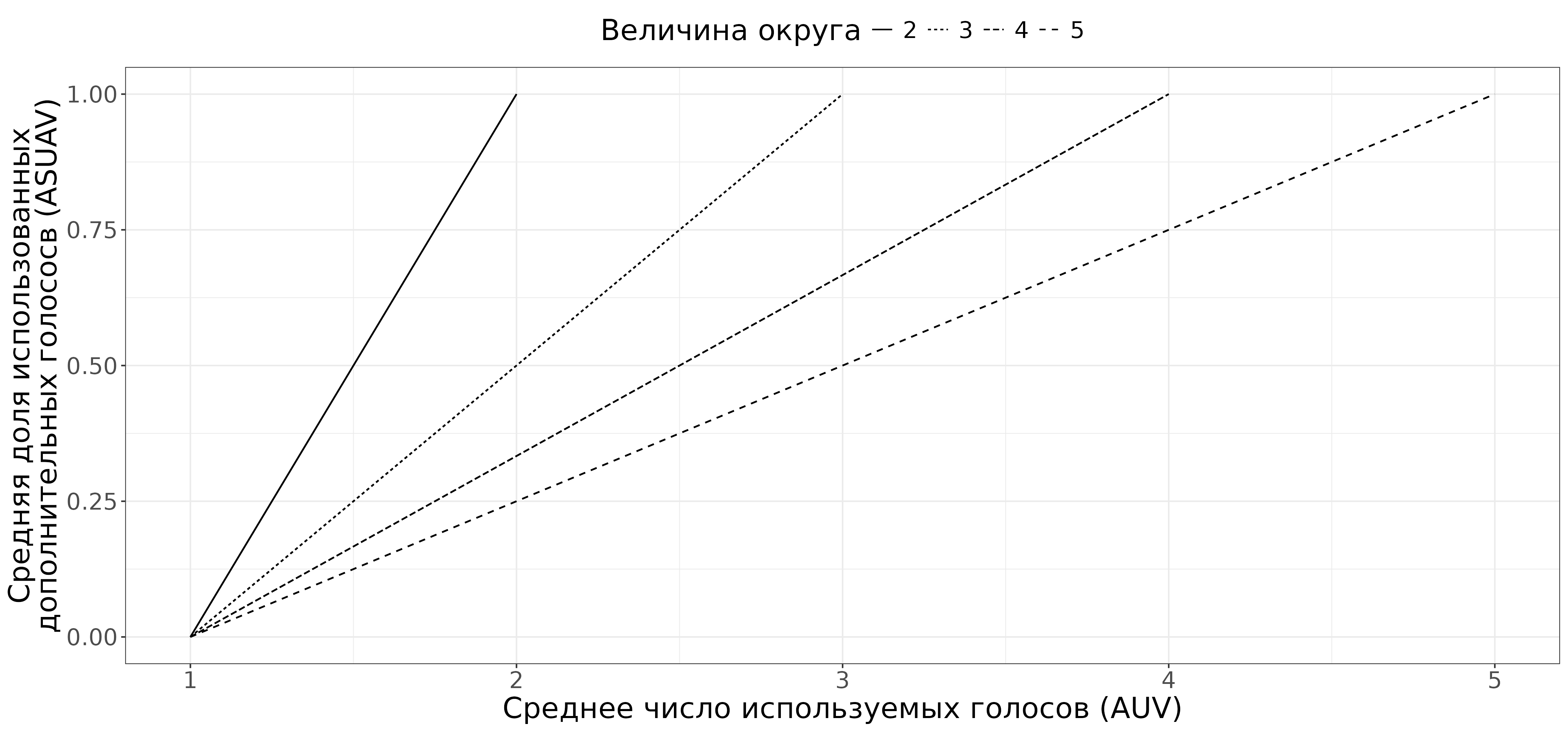
Рис. 1. Сравнение между разными подходами к оценке агрегированного числа используемых голосов
Немногочисленные существующие исследования используемого числа голосов в системе MNTV применяли иной подход к вычислению агрегированной оценки [16: 4–5; 25: 472]. При использовании данного способа минимальное значение шкалы зависит от величины округа, что может создавать неудобство при исследовании. Поэтому предложенная агрегированная оценка с помощью средней доли использованных дополнительных голосов представляется более практичной, поскольку обладает единым диапазоном.
Использование голосов избирателями на российских муниципальных выборах
Немногочисленные исследования каким-либо образом интерпретируют число используемых голосов избирателями в системе MNTV [8: 486–487; 10: 930; 16; 17: 115–116; 24: 225, 278–279, 300; 25: 472–474; 26]. Однако, как было продемонстрировано ранее, данный показатель является важной частью избирательной системы. Соответственно выявление условий, связанных с более или менее интенсивным использованием голосов, позволяет глубже понимать функционирование системы MNTV.
В данном исследовании предлагается сфокусироваться на случае российских муниципальных выборов с использованием системы MNTV. Предыдущие исследования отмечали, что в российском контексте данная избирательная система не приводит к ожидаемым последствиям [10]. «Эффект метлы», предполагающий получение одной партией всех мест в округе [22: 193], возникал на российских выборах значительно реже [10; 25: 138–139]. Данная особенность объяснялась тем, что избиратели не используют весь доступный им потенциал голосов [10: 429–430; 25: 138–139], что подтверждалось на агрегированных данных [10: 430; 24: 225, 278–279, 300; 25: 472–474; 26].
Нахождение свидетельств в пользу применения определенных моделей голосования российскими избирателями может помочь найти дополнительные объяснения редкой реализации «эффекта метлы». Так, приверженность избирателей «свободной» модели голосования сокращает возможности для его реализации, потому как избиратели чаще отбирают кандидатов ввиду разных критериев, а не только партии. Предпочтение электоратом «партийной» модели голосования, которая способствует возникновению «эффекта метлы», указывает на необходимость поиска дополнительных условий, снижающих возникновение данного последствия системы MNTV.
Необходимо отметить, что предложенные механизмы взаимодействия между электоральным спросом и предложением ранее были описаны в рамках индивидуального уровня. В случае агрегации предложенный подход также остается релевантным, если описанное взаимодействие имеет структурный характер. В таком случае увеличение числа избирателей, отказывающихся от части голосов на индивидуальном уровне, должно приводить к уменьшению агрегированной оценки используемых голосов, и наоборот. Учитывая это, выдвинем эмпирически проверяемые гипотезы, связывающие представленную ранее среднюю долю использованных дополнительных голосов с факторами электорального предложения для каждой из моделей голосования.
Если часть российских избирателей придерживается «партийной» модели голосования, то отсутствие части кандидатов предпочитаемой партии, при прочих равных условиях, должно снизить число используемых голосов среди ее сторонников. Данная гипотеза будет звучать так:
H1: Средняя доля использованных дополнительных голосов негативно связана с неполной представленностью партии кандидатами в избирательном округе
Данная гипотеза сформулирована в обобщенном виде и требует уточнения для отдельных партий в качестве дополнительных гипотез. Подходящими будут выступать партии, которые активно участвуют в выборах и потенциально имеют большое число сторонников. Под данные условия подходят основные парламентские партии: «Единая Россия», КПРФ, ЛДПР и «Справедливая Россия». Стоит ожидать, что если предполагаемая взаимосвязь существует, то она в первую очередь должна затрагивать данные партии. Также релевантным представляется включить партию «Яблоко», которая проводила активные избирательные кампании в муниципалитетах Москвы и Санкт-Петербурга. Для каждой из партий поставим дополнительную гипотезу:
H1a: Средняя доля использованных дополнительных голосов негативно связана с тем, что партия «Единая Россия» представлена в избирательном округе неполным числом кандидатов;
H1b: Средняя доля использованных дополнительных голосов негативно связана с тем, что КПРФ представлена в избирательном округе неполным числом кандидатов;
H1c: Средняя доля использованных дополнительных голосов негативно связана с тем, что ЛДПР представлена в избирательном округе неполным числом кандидатов;
H1d: Средняя доля использованных дополнительных голосов негативно связана с тем, что партия «Справедливая Россия» представлена в избирательном округе неполным числом кандидатов;
H1e: Средняя доля использованных дополнительных голосов негативно связана с тем, что партия «Яблоко» представлена в избирательном округе неполным числом кандидатов.
Если часть российских избирателей придерживается «свободной» модели голосования, то число используемых голосов будет снижаться в случае, когда отсутствуют кандидаты с необходимыми параметрами. Однако проблематичным представляется подбор такой переменной, которая бы одновременно измеряла соответствие спроса для всех избирателей, имеющих разное представление о критериях подбора кандидатов. Тем не менее возможно подобрать переменную, влияющую на вероятность удовлетворенности спроса каждого из избирателей. Представляется, что такой мерой является разнообразие среди кандидатов. Чем более разнородными являются баллотирующиеся, тем вероятнее, что избиратели с разными критериями отбора смогут найти подходящих им кандидатов, и наоборот. Тогда оформленная гипотеза звучит так:
H2: Средняя доля использованных дополнительных голосов положительно связана с разнообразием среди кандидатов в избирательном округе.
Под разнообразием в данном случае стоит понимать непохожесть кандидатов друг на друга. Возможно предложить два подхода к его измерению. Первый основан на использовании прокси-переменной в виде числа кандидатов в округе. Логично ожидать, что количество баллотирующихся должно быть монотонно и позитивно связано с разнообразием. Чем больше кандидатов в округе, тем в среднем выше уровень разнородности, и наоборот.
Второй подход предполагает вычисление меры частичного разнообразия с помощью количества уникальных профилей кандидатов, основанных на их социально-демографических характеристиках. Информация о них доступна избирателям при голосовании. Однако неизвестно, насколько они руководствуются ею при выборе кандидатов, а также пытаются ли они задействовать какие-либо дополнительные данные о них. В таком случае предложенное измерение является только ограниченной мерой оценки существующего разнообразия: чем больше кандидатов с уникальными профилями, тем выше в среднем разнообразие в округе, и наоборот.
Два предложенных подхода не являются идеальными способами измерения имеющегося разнообразия в округе. Однако представляется, что они должны быть скоррелированы с ним. Одновременное использование нескольких оценок позволяет обеспечить большую надежность результатов. Уточним ранее оформленную гипотезу с помощью дополнительных гипотез:
H2a: Средняя доля использованных дополнительных голосов положительно связана с числом кандидатов в округе;
H2b: Средняя доля использованных дополнительных голосов положительно связана с числом уникальных профилей в округе.
Таким образом, поставленные гипотезы направлены на проверку того, связана ли агрегированная оценка используемых голосов с факторами электорального предложения, которые релевантны разным моделям голосования. «Партийная» модель рассматривается в контексте гипотез H1, тогда как «свободная» модель анализируется в рамках гипотез H2. Устойчивость и существенность найденных взаимосвязей позволят опосредованным образом найти свидетельства в пользу применения различных моделей голосования в российском контексте.
Данные
Для проверки поставленных гипотез используются несколько наборов данных, охватывающих муниципальные выборы с использованием системы MNTV на российских выборах в период с конца 2007 г. по конец 2021 г. Данная избирательная система активно применяется на выборах во внутригородские избирательные образования (ВМО) Москвы и внутригородские муниципальные образования Санкт-Петербурга. В муниципалитетах различных уровней регионов России она также имеет достаточное распространение.
Однако на данный момент охватить все муниципалитеты российских регионов представляется проблематичным. Поэтому было принято решение сфокусироваться на отдельных городах. Данный выбор, с одной стороны, обоснован тем, что города являются компактными по размеру территориальными единицами с высокой плотностью избирателей. С другой стороны, количество городов ограничено и достаточно для проведения необходимого анализа. В изучаемый период города с точки зрения муниципального устройства могут являться как городскими округами (МО первого уровня), так и городскими поселениями (МО второго уровня). Поэтому в дальнейшем они обозначаются как городские муниципальные образования (ГМО).
Для ГМО в выборку включались только случаи, когда город обладал собственным представительным органом. Если муниципалитет реорганизовывался (включался в иной муниципалитет, преобразовался в округ иного типа, и т.д.), переставая обладать легислатурой, релевантной городу, то такая более крупная единица из выборки исключалась. Предыдущие случаи в выборке сохранялись. Для ВМО количество включенных случаев соответствует официальному территориальному устройству в период проведения выборов (из этого следует, что муниципалитеты «Новой Москвы» в анализе учитываются только с момента их присоединения к Москве, и т.д.)
Данная выборка охватила 1034 ГМО, 146 ВМО Москвы и 111 ВМО Санкт-Петербурга. В нее включались все доступные основные выборы в период с конца 2007 г. по конец 2021 г., охватившие три полных электоральных цикла. Вся информация об электоральной статистике и социально-демографических характеристиках кандидатов была взята с официального сайта ЦИК РФ, системы ГАС «Выборы».
Для целей анализа из ранее описанной выборки были отобраны только муниципалитеты, где выборы проходили с использованием системы MNTV. Они соответствовали нескольким критериям: 1) величина избирательного округа была равна 2, 3, 4, 5 или 10; 2) в пределах конкретных выборов величина избирательного округа была одинаковой; 3) не использовался вариант смешанной избирательной системы.
Величина избирательного округа для первого и второго условий была вычислена на основе количества кандидатов, которые были избраны по информации, указанной на сайте ГАС «Выборы». Соответственно для второго условия устанавливается, что в округах одного муниципалитета было избрано одинаковое число кандидатов. Очевидным недостатком такого подхода может быть то, что в случае указания неверной информации такого рода муниципалитет будет исключен из анализа. Однако, с одной стороны, это не является существенной проблемой для результатов анализа, так как ошибка такого рода, вероятно, возникает случайно. С другой стороны, данный метод показывает, что существует лишь небольшое число муниципалитетов с разной величиной округов. Соответственно, в условиях отсутствия детальной информации из официальных документов такой подход может являться оптимальным для выбора муниципалитетов с одинаковой величиной.
Таким образом, в итоговую выборку вошло 406 ГМО, 146 ВМО Москвы, 110 ВМО Санкт-Петербурга. Более подробная информация о числе муниципалитетов, использованных в анализе единожды, дважды или трижды для каждого из набора данных, представлена в приложении (приложение № 3). В качестве единицы анализа выступает отдельный избирательный участок.
Стратегия анализа
Опишем стратегию анализа, необходимую для проверки поставленных гипотез. В качестве зависимой переменной используется средняя доля использованных дополнительных голосов избирателями (\(ASUAV\)), измеренная на уровне отдельного избирательного участка. Данный вариант агрегированной оценки выбран ввиду его сопоставимости между округами с разной величиной.
Из выборки были исключены наблюдения, находящиеся вне диапазона (0, 1). Такое решение было принято ввиду возможных ошибок в изначальных данных электоральной статистики. В итоговую выборку вошло 14382 наблюдения для набора данных ГМО, 9012 наблюдений для ВМО Москвы, 5170 наблюдений для ВМО Санкт-Петербурга. Операционализируем объясняющие переменные для поставленных ранее гипотез.
Первая гипотеза (далее также «партийная» гипотеза) предполагает, что средняя доля использованных дополнительных голосов может быть связана с неполной представленностью партии в округе. В таком случае возможны три варианта присутствия партии: 1) число кандидатов соответствует величине округа; 2) число кандидатов меньше величины округа; 3) число кандидатов равно нулю. Таким образом, возможно сформировать две переменные, отражающие разные контрасты.
Выдвинутая «партийная» гипотеза предполагает сравнение случаев полной представленности с частичным вариантом. Для того чтобы избежать возможного смещения в пользу округов с каким-либо присутствием партии, необходимо учитывать также округа, где она не была представлена. Для этого необходимо учитывать в модели также сравнение между случаями с полной представленностью партии и его полным отсутствием.
Таким образом, формируются две дамми-переменные. В качестве референтной категории выступают округа с полным представительством. Первая переменная отражает, что партия обладает частичным представительством в округе. Вторая переменная демонстрирует, что партия не представлена в округе вовсе.
Вторая гипотеза (далее также «свободная» гипотеза) предполагает, что средняя доля использованных дополнительных голосов положительно связана с разнообразием характеристик кандидатов в избирательном округе. Для этого используются два варианта его оценки. Первый вариант подразумевает использование числа кандидатов на место в виде прокси-переменной существующего разнообразия. Для этого вычисляется отношение числа кандидатов в округе к величине избирательного округа, что уравнивает округа с разной величиной.
Второй вариант полагается на число уникальных профилей на место в качестве возможной оценки частичного разнообразия в округе. В данном случае профиль – это сочетание характеристик, потенциально оказывающих влияние на голосование избирателей: 1) пол [1]; 2) возраст [3]; 3) место проживания [20]; 4) инкумбентство [7]; 5) сектор занятости [15]; 6) наличие судимости [13]; 7) воспринимаемая этническая принадлежность [21]. Их категоризированные варианты формируют профиль кандидата (подробное описание процесса операционализации переменных и их категоризации представлено в приложениях № 1 и 2). Далее вычисляется уникальное число профилей кандидатов в округе, которое делится на величину избирательного округа.
Отсутствие большего числа предыдущих исследований по поводу использования голосов в MNTV затрудняет подбор необходимых контрольных переменных. В модели учитывается год проведения выборов. Представляется релевантным учитывать явку, которая потенциально отображает влияние мобилизации электората. Необходимым также представляется контролировать величину избирательного округа, чтобы учитывать возможно возникающие различия из-за разного числа голосов, доступных избирателям. В качестве контрольной переменной также выступает проведение параллельных выборов без учета выборов мэров и различных референдумов. Однако оценить взаимосвязь для параллельных выборов возможно лишь в случае ГМО. Выборы в ВМО достаточно часто организуются с другими выборами. Из-за этого отделить необходимые взаимосвязи от временного компонента становится проблематичным. Поэтому для ВМО факт проведения параллельных выборов не учитывается.
Для проверки поставленных гипотез используется бета-регрессионная многоуровневая смешанная модель. Бета-распределение является наиболее подходящим в случае, если зависимая переменная, как средняя доля использованных дополнительных голосов, представляет собой отношение и имеет ограниченный диапазон [9] (в качестве проверки устойчивости полученных оценок в Приложении № 8 представлено повторение анализа с помощью модели, которая учитывает диапазон зависимой переменной {0,1}). Многоуровневая модель необходима ввиду того, что используемые данные обладают естественной иерархической структурой и значения зависимой переменной близки в пределах групп. Для учета этого используется вложенная структура случайных эффектов, использующих случайную константу.
Опишем иерархическую структуру используемых данных: каждый избирательный участок (\(i\)) принадлежит некоторому избирательному округу (\(d\)), который включен в муниципалитет (\(m\)). Муниципалитет обладает временным индикатором, который отражает год проведения выборов (\(t\)). Имеющиеся данные не позволяют удостовериться в том, что избирательные участки и округа, принадлежащие одному муниципалитету, имеют одинаковые границы на разных выборах. Поэтому было принято решение ввести идентификатор выборов (\(g\)), комбинирующий муниципалитет (\(m\)) и дату проведения выборов (\(\tau\)).
Вложенная структура случайных эффектов предполагает, что каждый избирательный участок (\(i\), 1-й уровень) принадлежит некоторому избирательному округу (\(d\), 2-й уровень), который относится к конкретным выборам (\(g\), 3-й уровень). Такой подход подразумевает, что каждые отдельные выборы имеют собственные избирательные округа (\(dg\)) и избирательные участки (\(idg\)). Такой подход позволяет сохранить иерархическую структуру в пределах отдельных выборов, не предполагая постоянства границ. Временной компонент в модели учитывается с помощью введения фиксированных эффектов года проведения выборов (\(t\)).
Для того чтобы получить более осмысленные с точки зрения взаимосвязей оценки, используется REWB (The Random-Effects-Within-Between) подход [2]. Он позволяет разделить внутригрупповую и межгрупповую изменчивость предикторов [5; 23]. Применение такого рода «within-between» декомпозиции (подробная процедура описана в Приложении № 5) объясняющих переменных позволяет получить оценки на уровне избирательных округов в пределах отдельных выборов (within-\(g\)), что является основным фокусом данного исследования.
Таким образом, сформируем обобщенную формулу, подходящую для каждой из гипотез (формулы для каждой отдельной гипотезы представлены в Приложении № 6):
$$ 0 < ASUAV_{idg} < 1\quad(5) $$
$$ASUAV_{idg}|\mu_{idg},\phi \sim\mathrm{Beta}(\mu_{idg}\phi,(1-\mu_{idg})\phi)\quad(6)$$
$$\mathrm{logit}(\mu_{idg})=\beta_{W}(x_{dg}-\overline{x}_{g})+\beta_{B}(\overline{x}_{g}-\overline{x}_t)+\mathbf{Z}^{\mathrm{T}}_{idg}\delta+\lambda_{t}+v_{g}+u_{dg}\quad(7)$$
$$v_{g}\sim \mathcal{N}(0, \sigma^2_{v}), \quad u_{g}\sim \mathcal{N}(0, \sigma^2_{u})\quad(8) ,$$
где \(g\) – уникальный идентификатор выборов (\(m\), \(\tau\)), \(x_{dg}\) – значение объясняющей переменной \(x\) на уровне округа (\(d\)) в конкретные выборы (\(g\)), \(\overline{x}_g\) – среднее значение переменной \(x_{dg}\) по округам \(d\) в пределах \(g\), \(\overline{x}_t\) – среднее значение \(\overline{x}_g\) по всем выборам (\(g\)), проходящим в определенный год (\(t\)), \(\mathbf{Z}^{\mathrm{T}}_{idg}\) – вектор контрольных переменных, \(\lambda_{t}\) – фиксированный эффект годов, \(v_{g}\) – случайная константа идентификатора выборов (\(g\)), \(u_{dg}\) – случайная константа избирательного округа (\(d\)) внутри выборов (\(g\)).
Опишем интерпретацию переменных, полученных в рамках REWB подхода. Переменная \(\beta_{W}(x_{dg}-\overline{x}_{g})\) отражает различия между округами (\(d\)) в пределах одних конкретных выборов (\(g\)). Коэффициент \(\beta_{W}\) демонстрирует ожидаемое изменение \(\mathrm{logit}(\mu_{idg})\) при увеличении отклонения \((x_{dg}-\overline{x}_{g})\) на одну единицу, при прочих равных условиях. Переменная \(\beta_{B}(\overline{x}_{g}-\overline{x}_t)\) отражает различия между отдельными выборами (\(g\)) в пределах одного года (\(t\)). Коэффициент \(\beta_{B}\) демонстрирует ожидаемое изменение \(\mathrm{logit}(\mu_{idg})\) при увеличении отклонения \((\overline{x}_{g}-\overline{x}_t)\) на одну единицу, при прочих равных условиях. Таким образом, \(\beta_{W}\) позволяет получить оценку на уровне округов (\(d\)), тогда как \(\beta_{B}\) – на уровне отдельных выборов (\(g\)).
Результаты
Стратегия анализа, описанная в предыдущем разделе, была реализована на языке R с помощью пакета для построения смешанных многоуровневых моделей {glmmTMB}. Для более удобной интерпретации результатов полученные оценки представлены в виде средних предельных эффектов, которые были получены с помощью пакета {marginaleffects}.
Рассмотрим результаты, полученные в рамках «партийной» гипотезы H1. Данная гипотеза предполагает, что средняя доля использованных дополнительных голосов уменьшается в связи с уменьшением доступного партийного предложения. Для каждой из отобранных партий результаты представлены в отдельной таблице: таблица 1 для партии «Единая Россия», таблица 2 для партии КПРФ, таблица 3 для партии ЛДПР, таблица 4 для партии «Справедливая Россия», таблица 5 для партии «Яблоко».
Таблица 1. Результаты регрессии для партии «Единая Россия»
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,016** | 0,006 | 0,006 | -0,010 | 0,012 | 0,397 | -0,004 | 0,008 | 0,610 |
| Кол-во наблюдений | 14382 | 6210 | 5169 | ||||||
| Кол-во единиц: g | 854 | 261 | 325 | ||||||
| Кол-во единиц: dg | 3681 | 780 | 914 | ||||||
| Фиксированный R2 | 0,23 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,92 | 0,88 | ||||||
| SD (g) | 0,45 | 0,23 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,68 | 0,38 | 0,61 | ||||||
| ICC (dg) | 0,11 | 0,32 | 0,21 | ||||||
| ϕ | 12,51 | 14,15 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица 2. Результаты регрессии для КПРФ
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,010 | 0,007 | 0,150 | -0,016+ | 0,008 | 0,057 | -0,005 | 0,014 | 0,734 |
| Кол-во наблюдений | 14382 | 9012 | 5168 | ||||||
| Кол-во единиц: g | 854 | 387 | 324 | ||||||
| Кол-во единиц: dg | 3681 | 1205 | 913 | ||||||
| Фиксированный R2 | 0,24 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,89 | 0,88 | ||||||
| SD (g) | 0,45 | 0,21 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,68 | 0,3 | 0,61 | ||||||
| ICC (dg) | 0,12 | 0,3 | 0,2 | ||||||
| ϕ | 12,51 | 12,46 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица 3. Результаты регрессии для ЛДПР
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | 0,002 | 0,008 | 0,840 | 0,007 | 0,011 | 0,526 | 0,009 | 0,015 | 0,564 |
| Кол-во наблюдений | 14382 | 9012 | 5170 | ||||||
| Кол-во единиц: g | 854 | 387 | 326 | ||||||
| Кол-во единиц: dg | 3681 | 1205 | 915 | ||||||
| Фиксированный R2 | 0,22 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,89 | 0,88 | ||||||
| SD (g) | 0,45 | 0,21 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,68 | 0,31 | 0,61 | ||||||
| ICC (dg) | 0,11 | 0,29 | 0,2 | ||||||
| ϕ | 12,5 | 12,45 | 16,79 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица 4. Результаты регрессии для партии «Справедливая Россия»
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,001 | 0,009 | 0,944 | 0,001 | 0,015 | 0,932 | 0,000 | 0,009 | 0,967 |
| Кол-во наблюдений | 14382 | 9012 | 5170 | ||||||
| Кол-во единиц: g | 854 | 387 | 326 | ||||||
| Кол-во единиц: dg | 3681 | 1205 | 915 | ||||||
| Фиксированный R2 | 0,23 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,89 | 0,88 | ||||||
| SD (g) | 0,45 | 0,22 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,18 | ||||||
| ICC (g) | 0,68 | 0,32 | 0,61 | ||||||
| ICC (dg) | 0,12 | 0,29 | 0,2 | ||||||
| ϕ | 12,5 | 12,45 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица 5. Результаты регрессии для партии «Яблоко»
| ВМО, МСК | ВМО, СПб | |||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,005 | 0,015 | 0,755 | -0,024 | 0,016 | 0,123 |
| Кол-во наблюдений | 6103 | 3583 | ||||
| Кол-во единиц: g | 245 | 215 | ||||
| Кол-во единиц: dg | 739 | 612 | ||||
| Фиксированный R2 | 0,81 | 0,37 | ||||
| Условный R2 | 0,93 | 0,85 | ||||
| SD (g) | 0,19 | 0,31 | ||||
| SD (dg) | 0,2 | 0,17 | ||||
| ICC (g) | 0,33 | 0,58 | ||||
| ICC (dg) | 0,34 | 0,18 | ||||
| ϕ | 16,33 | 14,75 | ||||
| Контрольные переменные | × | × | ||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Стоит отметить, что помимо перечисленных ранее контрольных переменных, в данном случае в модель включено также число кандидатов на место, что позволяет учесть конкурентность в округе. Также модель содержит переменную, отражающую неполное представительство партии в округе. В некоторых случаях число наблюдений меньше, чем было заявлено ранее. Это связано с тем, что партии могли не участвовать в некоторых кампаниях вовсе. Например, кандидаты «Единой России» не участвовали в выборах ВМО Москвы в 2012 г. Анализ для партии «Яблоко» в ГМО не проводился, потому как партия участвовала в таких выборах слишком редко.
Обратимся к переменной «частичное присутствие кандидатов (W)», отражающей частичное представительство партии в округе (регрессионная таблица, включающая также «Частичное присутствие кандидатов (B)» представлена в Приложении № 7). Как можно заметить, в большинстве случаев взаимосвязь является статистически незначимой на конвенциональном альфа-уровне (p-value > 0,05). Исключением является случай «Единой России» в ГМО, где влияние статистически значимо (p-value < 0,01). На избирательных участках в округах, где партия «Единая Россия» в ГМО присутствовала лишь частично, средняя доля используемых дополнительных голосов меньше на 0,016 пункта. Соответственно большинство поставленных дополнительных гипотез не получают эмпирического подтверждения (H1b–H1e), тогда как гипотеза H1a подтверждается лишь частично.
Тем не менее для некоторых партий снижение «партийного» предложения также может быть связано с отказом от части голосов избирателями. Такие взаимосвязи обнаруживаются для КПРФ в ГМО (p-value = 0,15), КПРФ в ВМО Москвы (p-value = 0,06), «Яблоко» в ВМО Санкт-Петербурга (p-value = 0,12). Однако данные оценки могут указывать на возможную связь, но не позволяют быть уверенным в их устойчивости.
В целом проведенный анализ демонстрирует, что изменение «партийного» предложения систематически не связано со средней долей используемых дополнительных голосов. Соответственно гипотеза H1 имеет ограниченную эмпирическую поддержку. Предположение о том, что большинство российских избирателей активно полагаются на «партийную» модель голосования, не находит убедительного подтверждения в текущем исследовании. Потенциальным исключением может быть часть избирателей «Единой России», участвующих в выборах ГМО, которые, вероятно, чаще используют данную модель.
Рассмотрим результаты, полученные в рамках «свободной» гипотезы H2. Она подразумевает, что средняя доля использованных дополнительных голосов увеличивается в связи с разнообразием кандидатов в округе. В таблице 6 представлены результаты для гипотезы H2a, тогда как в таблице 7 находятся результаты для гипотезы H2b. Средние предельные эффекты представлены в нестандартизированном и стандартизированном видах.
Таблица 6. Результаты регрессии для оценки числа кандидатов на место
| ГМО, РФ | ВМО, МСК | ВМО, СПб | ||||
| Нестд. | Стд. | Нестд. | Стд. | Нестд. | Стд. | |
| оценка | оценка | оценка | оценка | оценка | оценка | |
| Число кандидатов на место (W) | 0,045*** | 0,022*** | 0,042*** | 0,019*** | 0,048*** | 0,022*** |
| (0,003) | (0,001) | (0,005) | (0,002) | (0,005) | (0,002) | |
| Кол-во наблюдений | 14382 | 9012 | 5170 | |||
| Кол-во единиц: g | 854 | 387 | 326 | |||
| Кол-во единиц: dg | 3681 | 1205 | 915 | |||
| Фиксированный R2 | 0,22 | 0,73 | 0,34 | |||
| Условный R2 | 0,84 | 0,89 | 0,88 | |||
| SD (g) | 0,45 | 0,22 | 0,32 | |||
| SD (dg) | 0,19 | 0,21 | 0,19 | |||
| ICC (g) | 0,68 | 0,32 | 0,61 | |||
| ICC (dg) | 0,11 | 0,29 | 0,2 | |||
| ϕ | 12,48 | 12,45 | 16,78 | |||
| Контрольные переменные | × | × | × | |||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица 7. Результаты регрессии для оценки числа уникальных профилей на место
| ГМО, РФ | ВМО, МСК | ВМО, СПб | ||||
| Нестд. | Стд. | Нестд. | Стд. | Нестд. | Стд. | |
| оценка | оценка | оценка | оценка | оценка | оценка | |
| Число уникальных профилей на место (W) | 0,044*** | 0,018*** | 0,039*** | 0,015*** | 0,053*** | 0,020*** |
| (0,004) | (0,002) | (0,005) | (0,002) | (0,006) | (0,002) | |
| Кол-во наблюдений | 14382 | 9012 | 5170 | |||
| Кол-во единиц: g | 854 | 387 | 326 | |||
| Кол-во единиц: dg | 3681 | 1205 | 915 | |||
| Фиксированный R2 | 0,2 | 0,72 | 0,32 | |||
| Условный R2 | 0,84 | 0,89 | 0,87 | |||
| SD (g) | 0,46 | 0,22 | 0,32 | |||
| SD (dg) | 0,19 | 0,21 | 0,19 | |||
| ICC (g) | 0,68 | 0,32 | 0,59 | |||
| ICC (dg) | 0,12 | 0,3 | 0,22 | |||
| ϕ | 12,48 | 12,45 | 16,79 | |||
| Контрольные переменные | × | × | × | |||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
«Число кандидатов на место (W)» положительно связано с увеличением средней доли использованных дополнительных голосов в каждом из наборов данных. Результаты значимы на конвенциональном альфа-уровне (p-value < 0,001). Увеличение на одну единицу числа кандидатов на место в округе связано со средним увеличением зависимой переменной на 0,042–0,048 пункта на избирательных участках. Аналогичным образом увеличение на одно стандартное отклонение данной переменной связано с увеличением зависимой переменной на 0,019–0,022 пункта на избирательных участках. Полученные результаты позволяют эмпирически подтвердить гипотезу H2a.
«Число уникальных профилей на место (W)» положительно связано с увеличением средней доли использованных дополнительных голосов в каждом из наборов данных. Результаты значимы на конвенциональном альфа-уровне (p-value < 0,001). Увеличение на одну единицу уникальных профилей на место в округе связано с увеличением зависимой переменной на 0,039–0,053 пункта на избирательных участках. Схожим образом увеличение на одно стандартное отклонение данной переменной связано с увеличением зависимой переменной на 0,015–0,02 пункта на избирательных участках. Найденные взаимосвязи позволяют эмпирически подтвердить гипотезу H2b.
Величина найденных взаимосвязей в обоих случаях представляется достаточно существенной. Тем не менее, необходимо принимать во внимание, что изменение показателей разнообразия на одну единицу соответствует достаточно значительному изменению состава кандидатов в округе. В таком случае стандартизированные оценки могут являться более сопоставимыми, однако их величина также является существенной.
Гипотеза H2 в целом получает эмпирическое подтверждение. Проведенный анализ демонстрирует, что увеличение разнообразия среди кандидатов в округе положительно связано со средней долей использованных дополнительных голосов избирателями. В пользу этого указывает согласованность полученных результатов, опирающихся на несколько наборов данных, и разные способы измерения разнообразия в округе. Исходя из перечисленного, предположение о распространенности «свободной» модели голосования среди российских избирателей находит убедительную поддержку в рамках данного исследования.
Однако нужно принимать во внимание, что найденные взаимосвязи как в случае «партийной», так и «свободной» гипотезы являются только первым приближением к изучению феномена использования голосов избирателями в MNTV в российском контексте. Полученные результаты должны с осторожностью использоваться для интерпретации соотношения используемых моделей голосования электоратом. Существенным ограничением является вывод на основе агрегированной метрики, что осложняет интерпретацию. Полученные оценки требуют дальнейшего уточнения, потому как, вероятно, могут не учитывать существующих общих причин между объясняющими переменными и зависимой. Такая особенность возникает как ввиду отсутствия исследований использования голосов избирателями, так и из-за недостатка более подробных данных. Из этого следует, что текущие оценки стоит интерпретировать только на ассоциативном уровне, учитывая описанные особенности.
Таким образом, с учетом всех существующих ограничений, полученные результаты дают общее представление об использовании моделей голосования российскими избирателями. Для показателей, связанных с «партийной» моделью голосования, не удается обнаружить последовательной взаимосвязи со средней долей использованных дополнительных голосов, тогда как в случае показателей, отражающих «свободную» модель голосования, найденные взаимосвязи являются устойчивыми и существенными. Соответственно, более обоснованным представляется предположение о том, что голосование российских избирателей в большей степени соответствует «свободной» модели, чем «партийной».
Заключение
Число используемых голосов избирателями является важным показателем избирательной системы MNTV, который может демонстрировать существующий разрыв между имеющимся электоральным спросом и предложением. Однако чаще всего его используют в качестве вспомогательного показателя и не пытаются объяснить, благодаря чему он может формироваться. В данном исследовании была предпринята попытка предложить теоретическую рамку, которая позволяет рассматривать число используемых голосов избирателями как результат соотношения между возникающим электоральным спросом и существующим предложением со стороны партий и кандидатов. Такой подход дает возможность оценить, с какими факторами предложения в большей степени связано изменение агрегированного числа используемых голосов избирателями.
Данная стратегия была использована для обнаружения свидетельств в пользу применения моделей голосования российскими избирателями на муниципальных выборах с использованием системы MNTV. Найденные взаимосвязи позволяют предположить, что агрегированная мера оценки числа используемых голосов в большей степени соотносится с реализацией «свободной», а не «партийной» модели голосования. Редкое возникновение «эффекта метлы» в таком случае может быть связано с большей распространенностью «свободной» модели, которая снижает возможность для его возникновения. Однако проведенное исследование имеет серьезные ограничения, которые необходимо учитывать при интерпретации выводов.
Поиск причин изменения числа голосов, используемых избирателями в MNTV, видится важной частью дальнейших исследований функционирования данной избирательной системы. В рамках предложенной концептуальной рамки возможно рассмотреть альтернативные варианты электорального спроса. Также важным представляется проведение исследований, позволяющих понять, благодаря чему возникают определенные варианты электорального спроса среди избирателей и в связи с чем может объясняться изменение существующего предложения. Результаты такого рода позволяют в дальнейшем получить более надежные выводы благодаря проработке более обоснованных теоретических связей.
Поступила в редакцию 15.03.2026, в окончательном виде 03.04.2026.
Приложение № 1. Операционализация переменных социально-демографических характеристик
Опишем операционализацию для переменных, которые были выбраны как минимально необходимый набор характеристик для проверки поставленной гипотезы. Все переменные были сконструированы на основе сведений о кандидатах, доступных на сайте ГАС “ВЫБОРЫ”. Для каждого кандидата доступны сведения, аналогичные предоставляемым в избирательном бюллетене. Информация бралась только с официального сайта и не дополнялась какими-либо источниками.
Каждому кандидату был присвоен пол на основе ФИО (мужской, женский). Возраст закодирован в виде шести категорий (18–24, 25–29, 30–44, 45–59, 60–74, 75 и старше). Границы групп не соотносятся с какой-либо общепринятой схемой. Однако такой подход позволяет учесть разные периоды карьерных стадий, которые могут быть важны для избирателей. Возраст кандидата был вычислен как разница между годом выборов и годом его рождения.
Место проживания представлено в виде двух категорий: проживает ли кандидат в муниципалитете (1), где проходят выборы, или нет (0). К сожалению, данные ВМО не являются настолько детализированными, и в них лишь указано, проживает ли кандидат в пределах Москвы или Санкт-Петербурга. Поэтому более точное определение места проживания на территории определенного ВМО невозможно. В данных случаях категория отражает, проживает ли кандидат в Москве или Санкт-Петербурге (1) или нет (0).
Для данных ГМО также стоит указать, что использовался консервативный подход при оценке места жительства. Если кандидат указывал, что он проживает в деревне, поселке, и т.д., который находится внутри или рядом с местом проведения выборов, то он получал значение 0. Такое решение было принято ввиду невозможности определить, воспринимают ли такого кандидата как жителя данной территории. Поэтому более надежным представляется ограничиться только теми, у кого указано проживание на территории, где проходят выборы.
Статус инкумбента представлен двумя категориями: занимает ли кандидат какое-либо депутатское место (1) или нет (0). Во избежание потери наблюдений такой статус было решено присваивать всем, кто указывал, что он является депутатом. Поэтому его получают даже те, кто ранее побеждал в другом муниципалитете.
Наличие судимости присваивалось, если указывалось, что кандидат имел какую-либо судимость (1).
На основе предоставляемой информации о месте работы кандидата и его должности возможно выделить тип места занятости кандидата. Для этого была выбрана упрощенная схема, опирающаяся на две категории: 1) кто является учредителем организации, в которой работает кандидат: государство или частные лица; 2) какова юридическая цель организации, где работает кандидат: коммерческая или некоммерческая. При условии отсутствия общепринятого подхода для такого рода классификации, данная схема представляется минималистичной и достаточной для выявления возможных различий. Представляется, что она позволяет описать типичные представления о возможной занятости кандидатов: занятость в коммерческом секторе, занятость в государственном секторе, занятость в некоммерческих организациях.
Пересечение предложенных категорий формирует четыре типа места занятости: 1) государственный некоммерческий сектор – бюджетные учреждения, не направленные на извлечение прибыли (школы, больницы, администрации и т.д.); 2) государственный коммерческий сектор – бюджетные учреждения направленные на извлечение прибыли (государственные и муниципальные предприятия); 3) частный некоммерческий сектор – частные учреждения, не направленные на извлечение прибыли (общественные организации, партии, ТСЖ и т.д.); 4) частный коммерческий сектор – частные учреждения, направленные на извлечение прибыли (ИП, ООО, ПАО и т.д.). К остаточной категории отнесены кандидаты, не имеющие занятости, – нетрудоустроенные (безработные, студенты, пенсионеры). Таким образом, тип места занятости описывается с помощью пяти категорий.
Необходимо отметить, что присвоение происходило по формальному статусу организации. Иными словами, если юридически она обладает статусом ПАО, то она будет отнесена к частному коммерческому сектору в любом случае. Ввиду ограниченности ресурсов такой подход является оптимальным, хотя и имеет свои ограничения. В случае, если предоставляемая информация о месте работы кандидата и его должности не позволяла определить тип занятости, то информация дополнялась с помощью вторичных источников. В крайнем случае, если и это не позволяло определить тип занятости, то выставлялся пропуск.
Воспринимаемая этническая принадлежность создается с помощью модели, которая была предложена Бессудновым и соавторами [4]. Данная модель использует имя и фамилию для определения вероятности отнесения к определенной этнической группе. Необходимо оговориться, что в данном случае подразумевается “воспринимаемая” (perceived) этничность. Имеющиеся имена и фамилии кандидатов были использованы для оценки вероятности быть отнесенными к некоторому этносу. Так как большая часть кандидатов по результатам модели могла бы быть отнесена к восточнославянскому этносу, то было принято решение дихотомизировать переменную. Для этого было указано, имеет ли кандидат восточнославянские ФИО или нет. Если вероятность принадлежности к данной группе превышала 0,5, то кандидат был отнесен к восточнославянской группе (1), и наоборот (0). Так как вопрос влияния данной переменной не является первостепенным для анализа, было решено использовать наиболее простое решение — дихотомизацию переменной.
Приложение № 2. Категоризация переменных социально-демографических характеристик
Для создания уникальной комбинации профилей необходимо перевести значения социально-демографических характеристик в числовые коды.
1. Пол: Мужской – 1, Женский – 0.
2. Возраст: 18–24 – 1; 25–29 – 2; 30–44 – 3; 45–59 – 4; 60–74 – 5; > 74 – 6.
3. Сектор занятости: государственный некоммерческий сектор – 1; государственный коммерческий сектор – 2; частный некоммерческий сектор – 3; частный коммерческий сектор – 4; нетрудоустроенные – 5;
4. Место проживания: в муниципалитете, где проводятся выборы, – 1; в другом муниципалитете – 0.
5. Восточнославянские ФИО: восточнославянские ФИО – 1; не восточнославянские ФИО – 0.
6. Статус инкумбента: инкумбент – 1; не инкумбент – 0.
7. Наличие судимости: судим – 1; не судим – 0.
Далее каждый кандидат получал комбинацию чисел, которая отражала его профиль. Например, кандидат мужского пола (1), 18–24 лет (1), занятый в государственном некоммерческом секторе (1), проживающий в муниципалитете, где проводятся выборы (1), с восточнославянскими ФИО (1), являющийся инкумбентом (1) и имеющий судимость (1), будет обладать таким профилем: 1111111. Далее на основании этих данных вычисляется уникальное число профилей на место.
Необходимо отметить, что для сектора занятости и места проживания имеется мизерное число пропусков: 5 пропусков по месту работы среди 16608 кандидатов в данных ВМО Москвы; 4 пропуска по месту жительства и 84 пропуска по месту работы среди 40283 кандидатов ГМО РФ; 3 пропуска по месту жительства и 48 пропусков по месту работы среди 13172 кандидатов ВМО СПб. Столь малое число пропусков, как представляется, не имеет смысла импутировать с помощью сложных методов. Поэтому они были восполнены с помощью наиболее частых категорий по данным переменным. Кандидатам без указания места жительства было проставлено проживание в месте, где проводились выборы (1). Для кандидатов без указания типа сектора занятости был выставлен частный коммерческий сектор (4).
Приложение № 3. Описательная статистика
3.1. ГМО
Таблица П1. Описательная статистика количества уникальных муниципалитетов, использованных в анализе, ГМО
| Кол-во раз использования | N=854 |
| 1 | 98 (11,5%) |
| 2 | 280 (32,8%) |
| 3 | 456 (53,4%) |
| 4 | 20 (2,3%) |
Таблица П2. Описательная статистика для присутствия партий, ГМО
| Партия | ЕР | КПРФ | ЛДПР | СР |
| N | 14382 | 14382 | 14382 | 14382 |
| Полное присутствие кандидатов | 11884 (82,6%) | 1700 (11,8%) | 1130 (7,9%) | 865 (6,0%) |
| Частичное присутствие кандидатов | 2346 (16,3%) | 8037 (55,9%) | 8141 (56,6%) | 6380 (44,4%) |
| Полное отсутствие кандидатов | 152 (1,1%) | 4645 (32,3%) | 5111 (35,5%) | 7137 (49,6%) |
Таблица П3. Описательная статистика для интервальных переменных, ГМО
| Доля пропущенных значений | Среднее | Стандартное отклонение | Мин. | Медиана | Макс. | |
| Средняя доля использованных дополнительных голосов | 0 | 0,6 | 0,2 | 0,0 | 0,6 | 1,0 |
| Явка (W) | 0 | -0,0 | 8,8 | -53,0 | -0,0 | 78,4 |
| Явка (B1) | 0 | 0,0 | 5,7 | -38,0 | -0,0 | 64,0 |
| Явка (B2) | 0 | -0,0 | 13,0 | -35,1 | -0,1 | 60,9 |
| Число кандидатов на место (W) | 0 | -0,0 | 0,5 | -2,0 | 0,0 | 2,6 |
| Число кандидатов на место (B) | 0 | 0,0 | 1,0 | -2,1 | -0,1 | 4,5 |
| Число уникальных профилей на место (W) | 0 | -0,0 | 0,4 | -1,9 | 0,0 | 2,5 |
| Число уникальных профилей на место (B) | 0 | 0,0 | 0,7 | -1,7 | -0,1 | 2,6 |
Таблица П4. Описательная статистика для категориальных переменных, ГМО
| Величина избирательного округа | N | % |
| 2 | 1747 | 12,1 |
| 3 | 2576 | 17,9 |
| 4 | 2851 | 19,8 |
| 5 | 7199 | 50,1 |
| 10 | 9 | 0,1 |
3.2. ВМО, МСК
Таблица П5. Описательная статистика количества муниципалитетов, включенных в анализ, ВМО, МСК
| Кол-во муниципалитетов | N=387 |
| 1 | 16 (4,1%) |
| 2 | 38 (9,8%) |
| 3 | 333 (86,0%) |
Таблица П6. Описательная статистика для присутствия партий, ВМО, МСК
| Партия | ЕР | КПРФ | ЛДПР | СР | "Яблоко" |
| N | 6210 | 9012 | 9012 | 9012 | 6103 |
| Полное присутствие кандидатов | 5109 (82,3%) | 2434 (27,0%) | 766 (8,5%) | 405 (4,5%) | 390 (6,4%) |
| Частичное присутствие кандидатов | 1021 (16,4%) | 4940 (54,8%) | 4590 (50,9%) | 4539 (50,4%) | 2690 (44,1%) |
| Полное отсутствие кандидатов | 80 (1,3%) | 1638 (18,2%) | 3656 (40,6%) | 4068 (45,1%) | 3023 (49,5%) |
Таблица П7. Описательная статистика для интервальных переменных, ВМО, МСК
| Доля пропущенных значений | Среднее | Стандартное отклонение | Мин. | Медиана | Макс. | |
| Средняя доля использованных дополнительных голосов | 0 | 0,5 | 0,2 | 0,0 | 0,6 | 1,0 |
| Явка (W) | 0 | 0,0 | 7,7 | -60,2 | -0,3 | 78,7 |
| Явка (B1) | 0 | -0,0 | 2,8 | -14,3 | -0,1 | 18,8 |
| Явка (B2) | 0 | -0,0 | 6,4 | -16,5 | -0,5 | 24,0 |
| Число кандидатов на место (W) | 0 | 0,0 | 0,4 | -1,7 | 0,0 | 1,9 |
| Число кандидатов на место (B) | 0 | 0,0 | 0,7 | -1,7 | -0,1 | 2,6 |
| Число уникальных профилей на место (W) | 0 | 0,0 | 0,4 | -1,5 | 0,0 | 1,3 |
| Число уникальных профилей на место (B) | 0 | -0,0 | 0,5 | -1,3 | -0,1 | 2,2 |
Таблица П8. Описательная статистика для категориальных переменных, ВМО, МСК
| Величина избирательного округа | N | % |
| 2 | 174 | 1,9 |
| 3 | 2572 | 28,5 |
| 4 | 2281 | 25,3 |
| 5 | 3979 | 44,2 |
| 10 | 6 | 0,1 |
3.3. ВМО, СПб
Таблица П9. Описательная статистика количества уникальных муниципалитетов, использованных в анализе, ВМО, СПб
| Кол-во муниципалитетов | N=326 |
| 1 | 1 (0,3%) |
| 2 | 6 (1,8%) |
| 3 | 315 (96,6%) |
| 4 | 4 (1,2%) |
Таблица П10. Описательная статистика для присутствия партий, ВМО, СПб
| Партия | ЕР | КПРФ | ЛДПР | СР | "Яблоко" |
| N | 5169 | 5168 | 5170 | 5170 | 3583 |
| Полное присутствие кандидатов | 4274 (82,7%) | 346 (6,7%) | 282 (5,5%) | 783 (15,1%) | 277 (7,7%) |
| Частичное присутствие кандидатов | 837 (16,2%) | 2670 (51,7%) | 2568 (49,7%) | 2607 (50,4%) | 840 (23,4%) |
| Полное отсутствие кандидатов | 58 (1,1%) | 2152 (41,6%) | 2320 (44,9%) | 1780 (34,4%) | 2466 (68,8%) |
Таблица П11. Описательная статистика для интервальных переменных, ВМО, СПб
| Доля пропущенных значений | Среднее | Стандартное отклонение | Мин. | Медиана | Макс. | |
| Средняя доля использованных дополнительных голосов | 0 | 0,6 | 0,1 | 0,0 | 0,6 | 1,0 |
| Явка (W) | 0 | -0,0 | 7,0 | -31,0 | -0,3 | 71,3 |
| Явка (B1) | 0 | -0,0 | 2,7 | -14,6 | -0,1 | 15,9 |
| Явка (B2) | 0 | -0,0 | 7,1 | -10,5 | -2,0 | 53,5 |
| Число кандидатов на место (W) | 0 | 0,0 | 0,5 | -2,6 | 0,0 | 1,7 |
| Число кандидатов на место (B) | 0 | -0,0 | 1,2 | -2,4 | -0,2 | 7,4 |
| Число уникальных профилей на место (W) | 0 | -0,0 | 0,4 | -1,4 | 0,0 | 1,4 |
| Число уникальных профилей на место (B) | 0 | 0,0 | 0,7 | -1,9 | -0,1 | 3,6 |
Таблица П12. Описательная статистика для категориальных переменных, ВМО, СПб
| Величина избирательного округа | N | % |
| 2 | 116 | 2,2 |
| 3 | 10 | 0,2 |
| 4 | 420 | 8,1 |
| 5 | 4582 | 88,6 |
| 10 | 42 | 0,8 |
Приложение № 4. Формульное представление объясняющих переменных
4.1. Частичное присутствие кандидатов
Частичное присутствие кандидатов (\(partial\_slate\)) в округе кодируется 1, если партия обладает хотя бы частичным представительством кандидатов в округе. В случае полного представительства партии в округе переменная кодируется как 0.
$$partial\_slate_{pdg} = \begin{cases} \text{1} & 0 < N_{dgp} < M_{dg} \\ \text{0} & N_{dgp} = M_{dg} \\ \end{cases},$$
где \(d\) – избирательный округ, \(g\) – уникальный идентификатор выборов (\(m, \tau\)), \(p\) – индикатор партии, \(N_{dgp}\) – число кандидатов партии \(p\) в округе \(d\) на конкретных выборах \(g\), \(M_{dg}\) – величина избирательного округа \(d\) на конкретных выборах \(g\).
4.2. Полное отсутствие кандидатов
Полное отсутствие кандидатов (\(no\_slate\)) в округе кодируется 1, если партия не имеет представительства в округе вовсе. В случае полного представительства партии в округе кодируется как 0.
$$no\_slate_{pdg} = \begin{cases} \text{1} & N_{dgp} = 0 \\ \text{0} & N_{dgp} = M_{dg} \\ \end{cases},$$
где \(p\) – индикатор партии, \(d\) – избирательный округ, \(g\) – уникальный идентификатор выборов (\(m, \tau\)), \(N_{dgp}\) – число кандидатов партии \(p\) в округе \(d\) на конкретных выборах \(g\), \(M_{dg}\) – величина избирательного округа \(d\) на конкретных выборах \(g\).
4.3. Число кандидатов на место
Число кандидатов на место (candidates per seat – \(CPS_{dg}\)) вычисляется как отношение числа кандидатов в округе (\(N_{dg}\)) к величине избирательного округа (\(M_{dg}\))
$$CPS_{dg} = \frac{N_{dg}}{M_{dg}},$$
где \(d\) – избирательный округ, \(g\) – уникальный идентификатор выборов (\(m, \tau\)), \(N_{dg}\) – число кандидатов в округе \(d\) на конкретных выборах \(g\), \(M_{dg}\) – величина избирательного округа \(d\) на конкретных выборах \(g\).
4.4. Число уникальных профилей на место
Алгоритм вычисления числа уникальных профилей (profiles per seat – \(PPS\)) на место:
1. Присвоить каждому кандидату профиль. Найти множество профилей в определенном округе \(d\) на выборах \(g\)
$$P_{dg} = \{profile_{cdg} \mid с = 1, 2, ..., N_{dg}\},$$
где \(d\) – избирательный округ, \(g\) – уникальный идентификатор выборов (\(m, \tau\)), \(c\) – идентификатор кандидата, \(N_{dg}\) – число кандидатов в округе \(d\) выборов \(g\).
2. Найти количество уникальных (отличающихся друг от друга) профилей среди представленных профилей (\(|P_{dg}|\))
$$U_{dg} = |P_{dg}|,$$
где \(d\) – избирательный округ, \(g\) – уникальный идентификатор выборов (\(m, \tau\)), \(|P_{dg}|\) – количество всех профилей в округе \(d\) выборов \(g\).
3. Вычислить уникальное число профилей на место как отношение числа уникальных профилей к величине округа
$$PPS_{dg} = \frac{U_{dg}}{M_{dg}},$$
где \(d\) – избирательный округ, \(g\) – уникальный идентификатор выборов (\(m, \tau\)), \(U_{dg}\) – количество всех уникальных профилей в округе \(d\) выборов \(g\), \(M_{dg}\) – величина избирательного округа.
Приложение № 5. Within-Between декомпозиция переменных
“Within-Between” декомпозиция позволяет разделить внутригрупповую и межгрупповую изменчивость предикторов. Это релевантно как для интервальных переменных [5], так и для бинарных [23]. Ниже для каждой из объясняющих переменных представлены формулы, позволяющие разложить их на отдельные компоненты. Такая же декомпозиция используется и для явки.
5.1. Частичное присутствие кандидатов
$$partial\_slate^{within}_{dgp} = partial\_slate_{dgp} - \overline{partial\_slate_{gp}}$$
$$partial\_slate^{between}_{gtp} = partial\_slate_{gp} - \overline{partial\_slate_{tp}}$$
5.2. Полное отсутствие кандидатов
$$no\_slate^{within}_{dgp} = no\_slate_{dgp} - \overline{no\_slate_{gp}}$$
$$no\_slate^{between}_{gtp} = no\_slate_{gp} - \overline{no\_slate_{tp}}$$
5.3. Число кандидатов на место
$$CPS_{dg}^{within} = CPS_{dg} - \overline{CPS_{g}}$$
$$CPS_{gt}^{between} = \overline{CPS_{g}} - \overline{CPS_{t}}$$
5.4. Число уникальных профилей на место
$$PPS_{dg}^{within} = PPS_{dg} - \overline{PPS_{g}}$$
$$PPS_{gt}^{between} = \overline{PPS_{g}} - \overline{PPS_{t}}$$
5.5. Явка
$$Turnout_{id}^{within} = Turnout_{i} - \overline{Turnout_{dg}}$$
$$Turnout_{dg}^{between} = \overline{Turnout_{d}} - \overline{Turnout_{dg}}$$
$$Turnout_{gt}^{between} = \overline{Turnout_{g}} - \overline{Turnout_{t}}$$
Приложение № 6. Полные регрессионные уравнения
Данное приложение демонстрирует полные формулы для каждой отдельной гипотезы с учетом применяемой ранее “between-within” декомпозиции:
6.1. “Партийная” гипотеза
$$0<\text{ASUAV}_{idgp}<1$$
$$\text{ASUAV}_{idgp}\mid \mu_{idgp},\phi \sim \mathrm{Beta}\!\bigl(\mu_{idgp}\phi,\,(1-\mu_{idgp})\phi\bigr)$$
$$\mathrm{logit}(\mu_{idgp}) = partial\_slate^{within}_{dgp} + partial\_slate^{between}_{gtp} + no\_slate^{within}_{dgp} + no\_slate^{between}_{gtp} + CPS_{dgp}^{within} + CPS_{gtp}^{between} + \mathbf{Z}_{idgp}^{\top}\boldsymbol{\delta} + \lambda_{t} + v_{g} + u_{dg}$$
6.2. “Свободная” гипотеза
6.2.1. Число кандидатов на место
$$0<\text{ASUAV}_{idg}<1$$
$$\text{ASUAV}_{idg}\mid \mu_{idg},\phi \sim \mathrm{Beta}\!\bigl(\mu_{idg}\phi,\,(1-\mu_{idg})\phi\bigr)$$
$$\mathrm{logit}(\mu_{idg}) = CPS_{dg}^{within} + CPS_{gt}^{between} + \mathbf{Z}_{idg}^{\top}\boldsymbol{\delta} + \lambda_{t} + v_{g} + u_{dg}$$
6.2.2. Число уникальных профилей на место
$$0<\text{ASUAV}_{idg}<1$$
$$\text{ASUAV}_{idg}\mid \mu_{idg},\phi \sim \mathrm{Beta}\!\bigl(\mu_{idg}\phi,\,(1-\mu_{idg})\phi\bigr)$$
$$\mathrm{logit}(\mu_{idg}) = PPS_{dg}^{within} + PPS_{gt}^{between} + \mathbf{Z}_{idg}^{\top}\boldsymbol{\delta} + \lambda_{t} + v_{g} + u_{dg}$$
Приложение № 7. Основные результаты, полная таблица. Средние предельные эффекты
Таблица П13. Результаты бета-регрессии для партии «Единая Россия»
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,016** | 0,006 | 0,006 | -0,010 | 0,012 | 0,397 | -0,004 | 0,008 | 0,610 |
| Частичное присутствие кандидатов (1) (B) | -0,021 | 0,019 | 0,255 | -0,014 | 0,015 | 0,359 | -0,037+ | 0,019 | 0,052 |
| Полное отсутствие кандидатов (1) (W) | -0,080* | 0,038 | 0,037 | -0,050 | 0,044 | 0,254 | -0,016 | 0,035 | 0,657 |
| Полное отсутствие кандидатов (1) (B) | 0,044 | 0,041 | 0,285 | 0,040 | 0,041 | 0,333 | -0,015 | 0,064 | 0,820 |
| Кол-во наблюдений | 14382 | 6210 | 5169 | ||||||
| Кол-во единиц: g | 854 | 261 | 325 | ||||||
| Кол-во единиц: dg | 3681 | 780 | 914 | ||||||
| Фиксированный R2 | 0,23 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,92 | 0,88 | ||||||
| SD (g) | 0,45 | 0,23 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,68 | 0,38 | 0,61 | ||||||
| ICC (dg) | 0,11 | 0,32 | 0,21 | ||||||
| ϕ | 12,51 | 14,15 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П14. Результаты бета-регрессии для КПРФ
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,010 | 0,007 | 0,150 | -0,016+ | 0,008 | 0,057 | -0,005 | 0,014 | 0,734 |
| Частичное присутствие кандидатов (1) (B) | -0,046+ | 0,024 | 0,053 | -0,015 | 0,013 | 0,246 | -0,020 | 0,030 | 0,498 |
| Полное отсутствие кандидатов (1) (W) | -0,011 | 0,009 | 0,215 | -0,018 | 0,012 | 0,131 | -0,006 | 0,015 | 0,684 |
| Полное отсутствие кандидатов (1) (B) | -0,070** | 0,024 | 0,003 | -0,060*** | 0,017 | <0,001 | -0,016 | 0,030 | 0,586 |
| Кол-во наблюдений | 14382 | 9012 | 5168 | ||||||
| Кол-во единиц: g | 854 | 387 | 324 | ||||||
| Кол-во единиц: dg | 3681 | 1205 | 913 | ||||||
| Фиксированный R2 | 0,24 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,89 | 0,88 | ||||||
| SD (g) | 0,45 | 0,21 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,68 | 0,3 | 0,61 | ||||||
| ICC (dg) | 0,12 | 0,3 | 0,2 | ||||||
| ϕ | 12,51 | 12,46 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П15. Результаты бета-регрессии для ЛДПР
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | 0,002 | 0,008 | 0,840 | 0,007 | 0,011 | 0,526 | 0,009 | 0,015 | 0,564 |
| Частичное присутствие кандидатов (1) (B) | -0,029 | 0,022 | 0,181 | 0,046* | 0,019 | 0,013 | 0,000 | 0,032 | 0,990 |
| Полное отсутствие кандидатов (1) (W) | 0,001 | 0,010 | 0,909 | -0,006 | 0,014 | 0,681 | 0,005 | 0,017 | 0,758 |
| Полное отсутствие кандидатов (1) (B) | -0,017 | 0,022 | 0,423 | 0,055* | 0,023 | 0,018 | -0,016 | 0,033 | 0,626 |
| Кол-во наблюдений | 14382 | 9012 | 5170 | ||||||
| Кол-во единиц: g | 854 | 387 | 326 | ||||||
| Кол-во единиц: dg | 3681 | 1205 | 915 | ||||||
| Фиксированный R2 | 0,22 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,89 | 0,88 | ||||||
| SD (g) | 0,45 | 0,21 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,68 | 0,31 | 0,61 | ||||||
| ICC (dg) | 0,11 | 0,29 | 0,2 | ||||||
| ϕ | 12,5 | 12,45 | 16,79 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П16. Результаты бета-регрессии для партии «Справедливая Россия»
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,001 | 0,009 | 0,944 | 0,001 | 0,015 | 0,932 | 0,000 | 0,009 | 0,967 |
| Частичное присутствие кандидатов (1) (B) | 0,030 | 0,032 | 0,343 | 0,007 | 0,021 | 0,752 | -0,025 | 0,021 | 0,241 |
| Полное отсутствие кандидатов (1) (W) | -0,005 | 0,011 | 0,665 | 0,002 | 0,016 | 0,893 | -0,016 | 0,013 | 0,215 |
| Полное отсутствие кандидатов (1) (B) | -0,002 | 0,031 | 0,945 | -0,003 | 0,023 | 0,910 | -0,009 | 0,021 | 0,657 |
| Кол-во наблюдений | 14382 | 9012 | 5170 | ||||||
| Кол-во единиц: g | 854 | 387 | 326 | ||||||
| Кол-во единиц: dg | 3681 | 1205 | 915 | ||||||
| Фиксированный R2 | 0,23 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,84 | 0,89 | 0,88 | ||||||
| SD (g) | 0,45 | 0,22 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,18 | ||||||
| ICC (g) | 0,68 | 0,32 | 0,61 | ||||||
| ICC (dg) | 0,12 | 0,29 | 0,2 | ||||||
| ϕ | 12,5 | 12,45 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П17. Результаты бета-регрессии для партии «Яблоко»
| ВМО, МСК | ВМО, СПб | |||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,005 | 0,015 | 0,755 | -0,024 | 0,016 | 0,123 |
| Частичное присутствие кандидатов (1) (B) | -0,035 | 0,024 | 0,151 | -0,042 | 0,039 | 0,284 |
| Полное отсутствие кандидатов (1) (W) | -0,010 | 0,017 | 0,557 | -0,003 | 0,016 | 0,878 |
| Полное отсутствие кандидатов (1) (B) | -0,056* | 0,028 | 0,042 | -0,079* | 0,035 | 0,026 |
| Кол-во наблюдений | 6103 | 3583 | ||||
| Кол-во единиц: g | 245 | 215 | ||||
| Кол-во единиц: dg | 739 | 612 | ||||
| Фиксированный R2 | 0,81 | 0,37 | ||||
| Условный R2 | 0,93 | 0,85 | ||||
| SD (g) | 0,19 | 0,31 | ||||
| SD (dg) | 0,2 | 0,17 | ||||
| ICC (g) | 0,33 | 0,58 | ||||
| ICC (dg) | 0,34 | 0,18 | ||||
| ϕ | 16,33 | 14,75 | ||||
| Контрольные переменные | × | × | ||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П18. Результаты бета-регрессии для оценки числа кандидатов на место
| ГМО, РФ | ВМО, МСК | ВМО, СПб | ||||
| Нестд. | Стд. | Нестд. | Стд. | Нестд. | Стд. | |
| Число кандидатов на место (W) | 0,045*** | 0,022*** | 0,042*** | 0,019*** | 0,048*** | 0,022*** |
| (0,003) | (0,001) | (0,005) | (0,002) | (0,005) | (0,002) | |
| Число кандидатов на место (B) | 0,051*** | 0,054*** | 0,059*** | 0,041*** | 0,040*** | 0,047*** |
| (0,004) | (0,005) | (0,005) | (0,003) | (0,004) | (0,005) | |
| Кол-во наблюдений | 14382 | 9012 | 5170 | |||
| Кол-во единиц: g | 854 | 387 | 326 | |||
| Кол-во единиц: dg | 3681 | 1205 | 915 | |||
| Фиксированный R2 | 0,22 | 0,73 | 0,34 | |||
| Условный R2 | 0,84 | 0,89 | 0,88 | |||
| SD (g) | 0,45 | 0,22 | 0,32 | |||
| SD (dg) | 0,19 | 0,21 | 0,19 | |||
| ICC (g) | 0,68 | 0,32 | 0,61 | |||
| ICC (dg) | 0,11 | 0,29 | 0,2 | |||
| ϕ | 12,5 | 12,45 | 16,78 | |||
| Контрольные переменные | × | × | × | |||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П19. Результаты бета-регрессии для оценки числа уникальных профилей на место
| ГМО, РФ | ВМО, МСК | ВМО, СПб | ||||
| Нестд. | Стд. | Нестд. | Стд. | Нестд. | Стд. | |
| Число уникальных профилей на место (W) | 0,044*** | 0,018*** | 0,039*** | 0,015*** | 0,053*** | 0,020*** |
| (0,004) | (0,002) | (0,005) | (0,002) | (0,006) | (0,002) | |
| Число уникальных профилей на место (B) | 0,072*** | 0,050*** | 0,074*** | 0,040*** | 0,064*** | 0,047*** |
| (0,006) | (0,004) | (0,006) | (0,003) | (0,007) | (0,005) | |
| Кол-во наблюдений | 14382 | 9012 | 5170 | |||
| Кол-во единиц: g | 854 | 387 | 326 | |||
| Кол-во единиц: dg | 3681 | 1205 | 915 | |||
| Фиксированный R2 | 0,2 | 0,72 | 0,32 | |||
| Условный R2 | 0,84 | 0,89 | 0,87 | |||
| SD (g) | 0,46 | 0,22 | 0,32 | |||
| SD (dg) | 0,19 | 0,21 | 0,19 | |||
| ICC (g) | 0,68 | 0,32 | 0,59 | |||
| ICC (dg) | 0,12 | 0,3 | 0,22 | |||
| ϕ | 12,48 | 12,45 | 16,79 | |||
| Контрольные переменные | × | × | × | |||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Приложение № 8. Дополнительные результаты, полная таблица. Средние предельные эффекты
Дополнительные результаты повторяют основной анализ, описанный в статье и более подробно представленный в приложении № 7. Единственным отличием является использование пакета упорядоченной бета-регрессии (ordered beta regression) [14] вместо бета-регрессии. Регрессия такого рода позволяет обрабатывать диапазон (0, 1). В таком случае наблюдения, исключенные ранее, включаются в анализ. Учет этих наблюдений не изменяет результаты основного анализа. Таким образом, полученные результаты устойчивы.
Таблица П20. Результаты порядковой бета-регрессии для партии «Единая Россия»
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,016** | 0,006 | 0,006 | -0,010 | 0,012 | 0,397 | -0,004 | 0,008 | 0,610 |
| Частичное присутствие кандидатов (1) (B) | -0,021 | 0,019 | 0,255 | -0,014 | 0,015 | 0,359 | -0,037+ | 0,019 | 0,052 |
| Полное отсутствие кандидатов (1) (W) | -0,080* | 0,038 | 0,037 | -0,050 | 0,044 | 0,254 | -0,016 | 0,035 | 0,657 |
| Полное отсутствие кандидатов (1) (B) | 0,044 | 0,041 | 0,285 | 0,040 | 0,041 | 0,333 | -0,015 | 0,064 | 0,820 |
| Кол-во наблюдений | 14875 | 6303 | 5197 | ||||||
| Кол-во единиц: g | 875 | 261 | 325 | ||||||
| Кол-во единиц: dg | 3782 | 780 | 915 | ||||||
| Фиксированный R2 | 0,13 | 0,73 | 0,35 | ||||||
| Условный R2 | 0,92 | 0,92 | 0,88 | ||||||
| SD (g) | 0,81 | 0,22 | 0,32 | ||||||
| SD (dg) | 0,18 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,87 | 0,37 | 0,61 | ||||||
| ICC (dg) | 0,04 | 0,32 | 0,2 | ||||||
| ϕ | 12,59 | 14,14 | 16,79 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П21. Результаты порядковой бета-регрессии для КПРФ
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,010 | 0,007 | 0,150 | -0,016+ | 0,008 | 0,057 | -0,005 | 0,014 | 0,734 |
| Частичное присутствие кандидатов (1) (B) | -0,046+ | 0,024 | 0,053 | -0,015 | 0,013 | 0,246 | -0,020 | 0,030 | 0,498 |
| Полное отсутствие кандидатов (1) (W) | -0,011 | 0,009 | 0,215 | -0,018 | 0,012 | 0,131 | -0,006 | 0,015 | 0,684 |
| Полное отсутствие кандидатов (1) (B) | -0,070** | 0,024 | 0,003 | -0,060*** | 0,017 | <0,001 | -0,016 | 0,030 | 0,586 |
| Кол-во наблюдений | 14875 | 9159 | 5196 | ||||||
| Кол-во единиц: g | 875 | 387 | 324 | ||||||
| Кол-во единиц: dg | 3782 | 1205 | 914 | ||||||
| Фиксированный R2 | 0,14 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,92 | 0,89 | 0,88 | ||||||
| SD (g) | 0,81 | 0,21 | 0,32 | ||||||
| SD (dg) | 0,19 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,86 | 0,3 | 0,61 | ||||||
| ICC (dg) | 0,05 | 0,3 | 0,2 | ||||||
| ϕ | 12,59 | 12,45 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П22. Результаты порядковой бета-регрессии для ЛДПР
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | 0,002 | 0,008 | 0,840 | 0,007 | 0,011 | 0,526 | 0,009 | 0,015 | 0,564 |
| Частичное присутствие кандидатов (1) (B) | -0,029 | 0,022 | 0,181 | 0,046* | 0,019 | 0,013 | 0,000 | 0,032 | 0,990 |
| Полное отсутствие кандидатов (1) (W) | 0,001 | 0,010 | 0,909 | -0,006 | 0,014 | 0,681 | 0,005 | 0,017 | 0,758 |
| Полное отсутствие кандидатов (1) (B) | -0,017 | 0,022 | 0,423 | 0,055* | 0,023 | 0,018 | -0,016 | 0,033 | 0,626 |
| Кол-во наблюдений | 14875 | 9159 | 5198 | ||||||
| Кол-во единиц: g | 875 | 387 | 326 | ||||||
| Кол-во единиц: dg | 3782 | 1205 | 916 | ||||||
| Фиксированный R2 | 0,14 | 0,73 | 0,34 | ||||||
| Условный R2 | 0,92 | 0,89 | 0,88 | ||||||
| SD (g) | 0,81 | 0,21 | 0,32 | ||||||
| SD (dg) | 0,18 | 0,21 | 0,19 | ||||||
| ICC (g) | 0,86 | 0,31 | 0,61 | ||||||
| ICC (dg) | 0,05 | 0,3 | 0,2 | ||||||
| ϕ | 12,59 | 12,44 | 16,79 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П23. Результаты порядковой бета-регрессии для партии «Справедливая Россия»
| ГМО, РФ | ВМО, МСК | ВМО, СПб | |||||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,001 | 0,009 | 0,944 | 0,001 | 0,015 | 0,932 | 0,000 | 0,009 | 0,967 |
| Частичное присутствие кандидатов (1) (B) | 0,030 | 0,032 | 0,343 | 0,007 | 0,021 | 0,752 | -0,025 | 0,021 | 0,241 |
| Полное отсутствие кандидатов (1) (W) | -0,005 | 0,011 | 0,665 | 0,002 | 0,016 | 0,893 | -0,016 | 0,013 | 0,215 |
| Полное отсутствие кандидатов (1) (B) | -0,002 | 0,031 | 0,945 | -0,003 | 0,023 | 0,910 | -0,009 | 0,021 | 0,657 |
| Кол-во наблюдений | 14875 | 9159 | 5198 | ||||||
| Кол-во единиц: g | 875 | 387 | 326 | ||||||
| Кол-во единиц: dg | 3782 | 1205 | 916 | ||||||
| Фиксированный R2 | 0,14 | 0,72 | 0,34 | ||||||
| Условный R2 | 0,92 | 0,89 | 0,88 | ||||||
| SD (g) | 0,8 | 0,22 | 0,32 | ||||||
| SD (dg) | 0,18 | 0,21 | 0,18 | ||||||
| ICC (g) | 0,86 | 0,31 | 0,61 | ||||||
| ICC (dg) | 0,05 | 0,29 | 0,2 | ||||||
| ϕ | 12,59 | 12,44 | 16,78 | ||||||
| Контрольные переменные | × | × | × | ||||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П24. Результаты порядковой бета-регрессии для партии «Яблоко»
| ВМО, МСК | ВМО, СПб | |||||
| Оценка | Ст. Ошибка | p-value | Оценка | Ст. Ошибка | p-value | |
| Частичное присутствие кандидатов (1) (W) | -0,005 | 0,015 | 0,755 | -0,024 | 0,016 | 0,123 |
| Частичное присутствие кандидатов (1) (B) | -0,035 | 0,024 | 0,151 | -0,042 | 0,039 | 0,284 |
| Полное отсутствие кандидатов (1) (W) | -0,010 | 0,017 | 0,557 | -0,003 | 0,016 | 0,878 |
| Полное отсутствие кандидатов (1) (B) | -0,056* | 0,028 | 0,042 | -0,079* | 0,035 | 0,026 |
| Кол-во наблюдений | 6165 | 3601 | ||||
| Кол-во единиц: g | 245 | 215 | ||||
| Кол-во единиц: dg | 739 | 612 | ||||
| Фиксированный R2 | 0,81 | 0,37 | ||||
| Условный R2 | 0,93 | 0,85 | ||||
| SD (g) | 0,19 | 0,31 | ||||
| SD (dg) | 0,2 | 0,17 | ||||
| ICC (g) | 0,33 | 0,58 | ||||
| ICC (dg) | 0,34 | 0,18 | ||||
| ϕ | 16,34 | 14,75 | ||||
| Контрольные переменные | × | × | ||||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П25. Результаты порядковой бета-регрессии для оценки числа кандидатов на место
| ГМО, РФ | ВМО, МСК | ВМО, СПб | ||||
| Нестд. | Стд. | Нестд. | Стд. | Нестд. | Стд. | |
| Число кандидатов на место (W) | 0,045*** | 0,022*** | 0,042*** | 0,019*** | 0,048*** | 0,022*** |
| (0,003) | (0,001) | (0,005) | (0,002) | (0,005) | (0,002) | |
| Число кандидатов на место (B) | 0,051*** | 0,054*** | 0,059*** | 0,041*** | 0,040*** | 0,047*** |
| (0,004) | (0,005) | (0,005) | (0,003) | (0,004) | (0,005) | |
| Кол-во наблюдений | 14875 | 9159 | 5198 | |||
| Кол-во единиц: g | 875 | 387 | 326 | |||
| Кол-во единиц: dg | 3782 | 1205 | 916 | |||
| Фиксированный R2 | 0,13 | 0,72 | 0,34 | |||
| Условный R2 | 0,92 | 0,89 | 0,88 | |||
| SD (g) | 0,81 | 0,22 | 0,32 | |||
| SD (dg) | 0,18 | 0,21 | 0,19 | |||
| ICC (g) | 0,86 | 0,32 | 0,61 | |||
| ICC (dg) | 0,05 | 0,29 | 0,2 | |||
| ϕ | 12,59 | 12,44 | 16,79 | |||
| Контрольные переменные | × | × | × | |||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Таблица П26. Результаты порядковой бета-регрессии для оценки числа уникальных профилей на место
| ГМО, РФ | ВМО, МСК | ВМО, СПб | ||||
| Нестд. | Стд. | Нестд. | Стд. | Нестд. | Стд. | |
| Число уникальных профилей на место (W) | 0,044*** | 0,018*** | 0,039*** | 0,015*** | 0,053*** | 0,020*** |
| (0,004) | (0,002) | (0,005) | (0,002) | (0,006) | (0,002) | |
| Число уникальных профилей на место (B) | 0,072*** | 0,050*** | 0,074*** | 0,040*** | 0,064*** | 0,047*** |
| (0,006) | (0,004) | (0,006) | (0,003) | (0,007) | (0,005) | |
| Кол-во наблюдений | 14875 | 9159 | 5198 | |||
| Кол-во единиц: g | 875 | 387 | 326 | |||
| Кол-во единиц: dg | 3782 | 1205 | 916 | |||
| Фиксированный R2 | 0,12 | 0,71 | 0,33 | |||
| Условный R2 | 0,92 | 0,89 | 0,88 | |||
| SD (g) | 0,81 | 0,22 | 0,32 | |||
| SD (dg) | 0,19 | 0,22 | 0,19 | |||
| ICC (g) | 0,86 | 0,32 | 0,6 | |||
| ICC (dg) | 0,05 | 0,3 | 0,22 | |||
| ϕ | 12,56 | 12,44 | 16,79 | |||
| Контрольные переменные | × | × | × | |||
+ p < 0,1, * p < 0,05, ** p < 0,01, *** p < 0,001
Список литературы
- Anzia S.F., Bernhard R. Gender Stereotyping and the Electoral Success of Women Candidates: New Evidence from Local Elections in the United States. – British Journal of Political Science. 2022. Vol. 52. No. 4. P. 1544–1563.
- Bell A., Fairbrother M., Jones K. Fixed and random effects models: making an informed choice. – Quality & Quantity. 2019. Vol. 53. No. 2. P. 1051–1074.
- Belschner J. Too young to win? Exploring the sources of age-related electoral disadvantage. – Electoral Studies. 2024. Vol. 88. P. 102748.
- Bessudnov A., Tarasov D., Panasovets V., Kostenko V., Smirnov I., Uspenskiy V. Predicting perceived ethnicity with data on personal names in Russia. – Journal of Computational Social Science. 2023. Vol. 6. No. 2. P. 589–608.
- Brincks A.M., Enders C.K, Llabre M.M., Bulotski-Shearer R.J., Prado G., Feaster D.J. Centering predictor variables in three-level contextual models. – Multivariate Behavioral Research. 2017. Vol. 52. No. 2. P. 149–163.
- Colomer J.M. On the origins of electoral systems and political parties: The role of elections in multi-member districts. – Electoral Studies. 2007. Vol. 26. No. 2. P. 262–273.
- Cox G.W., Morgenstern S. The Incumbency Advantage in Multimember Districts: Evidence from the U. S. States. – Legislative Studies Quarterly. 1995. Vol. 20. No. 3. P. 329.
- Denver D.T., Hands H.T.G. Differential party votes in multi-member electoral divisions. – Political Studies. 1975. Vol. 23. No. 4. P. 486–490.
- Ferrari S., Cribari-Neto F. Beta regression for modelling rates and proportions. – Journal of Applied Statistics. 2004. Vol. 31. No. 7. P. 799–815.
- Golosov G.V. Electoral Systems and Party Formation in Russia: A Cross-Regional Analysis. – Comparative Political Studies. 2003. Vol. 36. No. 8. P. 912–935.
- Herron E.S., Pekkanen R.J., Shugart M.S. Terminology and Basic Rules of Electoral Systems. – The Oxford handbook of electoral systems. New York: Oxford University Press, 2018. P. 1–20.
- Hicken A. Aggregation, Nationalization, and the Number of Parties in Thailand. – Building Party Systems in Developing Democracies. Cambridge: Cambridge University Press, 2009. P. 86–115.
- Khemka A. Why do voters elect criminal politicians? – European Journal of Political Economy. 2024. Vol. 82. P. 102527.
- Kubinec R. Ordered beta regression: a parsimonious, well-fitting model for continuous data with lower and upper bounds. – Political Analysis. 2023. Vol. 31. No. 4. P. 519–536.
- Mechtel M. It’s the occupation, stupid! Explaining candidates’ success in low-information elections. – European Journal of Political Economy. 2014. Vol. 33. P. 53–70.
- Rallings C., Thrasher M., Borisyuk G. Unused Votes in English Local Government Elections: Effects and Explanations. – Journal of Elections, Public Opinion and Parties. 2009. Vol. 19. No. 1. P. 1–23.
- Rallings C., Thrasher M., Gunter C. Patterns of voting choice in multimember districts: the case of english local elections. – Electoral Studies. 1998. Vol. 17. No. 1. P. 111–128.
- Reynolds A., Reilly B., Ellis A. 3. The Systems And Their Consequences. – Electoral system design: the new International IDEA handbook. Stockholm: International IDEA, 2005. P. 35–127.
- Scarrow H.A. The impact of at-large elections: vote dilution or choice dilution? – Electoral Studies. 1999. Vol. 18. No. 4. P. 557–567.
- Schulte-Cloos J., Bauer P.C. Local Candidates, Place-Based Identities, and Electoral Success. – Political Behavior. 2023. Vol. 45. No. 2. P. 679–698.
- Thrasher M., Borisyuk G., Rallings C., Webber R. Candidate ethnic origins and voter preferences: examining name discrimination in local elections in Britain. – British Journal of Political Science. 2017. Vol. 47. No. 2. P. 413–435.
- Weaver L. Semi-Proportional and Proportional Representation Systems in the United States. – Choosing an electoral system: issues and alternatives. Westport, Conn.: Praeger, 1984. P. 191–206.
- Yaremych H.E., Preacher K.J., Hedeker D. Centering categorical predictors in multilevel models: best practices and interpretation. – Psychological Methods. 2023. Vol. 28. No. 3. P. 613–630.
- Любарев А.Е. Выборы в Москве: опыт двенадцати лет, 1989–2000. М.: Стольный град, 2001. 416 с.
- Любарев А.Е. Избирательные системы: российский и мировой опыт. М.: Новое литературное обозрение, 2016. 631 с.
- Любарев А.Е. Российские муниципальные выборы через призму электоральной статистики. – Электоральная политика. 2022. № 2 (8). С. 1. - https://electoralpolitics.org/ru/articles/rossiiskie-munitsipalnye-vybory-cherez-prizmu-elektoralnoi-statistiki/